第4节 Go语言项目设计
❤️💕💕During the winter vacation, I followed up and learned two projects: tiktok project and IAM project, and summarized and practiced the CloudNative project and Go language. I learned a lot in the process.Myblog:http://nsddd.top
[TOC]
目录结构
命名要求和规范:
- 命名清晰:目录命名要清晰、简洁,不要太长,也不要太短,目录名要能清晰地表达出该目录实现的功能,并且目录名最好用单数。一方面是因为单数足以说明这个目录的功能,另一方面可以统一规范,避免单复混用的情况。
- 功能明确:一个目录所要实现的功能应该是明确的、并且在整个项目目录中具有很高的辨识度。也就是说,当需要新增一个功能时,我们能够非常清楚地知道把这个功能放在哪个目录下。
- 全面性:目录结构应该尽可能全面地包含研发过程中需要的功能,例如文档、脚本、源码管理、API 实现、工具、第三方包、测试、编译产物等。
- 可观测性:项目规模一定是从小到大的,所以一个好的目录结构应该能够在项目变大时,仍然保持之前的目录结构。
- 可扩展性:每个目录下存放了同类的功能,在项目变大时,这些目录应该可以存放更多同类功能。举个例子,有如下目录结构:
💡简单的一个案例如下:
$ ls internal/
app pkg README.md
internal 目录下有三个文件,internal 目录用来实现内部代码,app 和 pkg 目录下的所有文件都属于内部代码。如果 internal 目录不管项目大小,永远只有 2 个文件 app 和 pkg,那么就说明 internal 目录是不可扩展的。
相反,如果 internal 目录下直接存放每个组件的源码目录(一个项目可以由一个或多个组件组成),当项目变大、组件增多时,可以将新增加的组件代码存放到 internal 目录,这时 internal 目录就是可扩展的。例如:
$ ls internal/
apiserver authzserver iamctl pkg pump watcher
根据功能,我们可以将目录结构分为结构化目录结构和平铺式目录结构两种。 结构化目录结构主要用在 Go 应用中,相对来说比较复杂;而平铺式目录结构主要用在 Go 包中,相对来说比较简单。
平铺式结构
一个 Go 项目可以是一个应用,也可以是一个代码 框架 / 库,当项目是代码 框架 / 库 时,比较适合采用平铺式目录结构。
平铺方式就是在项目的根目录下存放项目的代码,整个目录结构看起来更像是一层的,这种方式在很多框架 / 库中存在,使用这种方式的好处是引用路径长度明显减少,比如 github.com/marmotedu/log/pkg/options,可缩短为 github.com/marmotedu/log/options。例如 log 包 github.com/golang/glog 就是平铺式的,目录如下:
$ ls glog/
glog_file.go glog.go glog_test.go LICENSE README
结构式结构
当前 Go 社区比较推荐的结构化目录结构是 project-layout 。虽然它并不是官方和社区的规范,但因为组织方式比较合理,被很多 Go 开发人员接受。所以,我们可以把它当作是一个事实上的规范。
开发一个Go语言项目,应该包含哪些功能:
- 项目介绍:README.md。
- 客户端:xxxctl。
- API 文档。
- 构建配置文件,CICD 配置文件。
- CHANGELOG。
- 项目配置文件。
- kubernetes 部署定义文件(未来容器化是趋势,甚至会成为服务部署的事实标准,所以目录结构中需要有存放 kubernetes 定义文件的目录)。
- Dockerfile 文件。
- systemd/init 部署配置文件(物理机/虚拟机部署方式需要)。
- 项目文档。
- commit message 格式检查或者其他 githook。
- 请求参数校验。
- 命令行 flag。
- 共享包:
- 外部项目可导入。
- 只有子项目可导入。
- storage 接口。
- 项目管理:Makefile,完成代码检查、构建、打包、测试、部署等。
- 版权声明。
- _output 目录(编译、构建产物)。
- 引用的第三方包。
- 脚本文件(可能会借助脚本,实现一些源码管理、构建、生成等功能)。
- 测试文件。
IAM 项目规范:
├── api
│ ├── openapi
│ └── swagger
├── build
│ ├── ci
│ ├── docker
│ │ ├── iam-apiserver
│ │ ├── iam-authz-server
│ │ └── iam-pump
│ ├── package
├── CHANGELOG
├── cmd
│ ├── iam-apiserver
│ │ └── apiserver.go
│ ├── iam-authz-server
│ │ └── authzserver.go
│ ├── iamctl
│ │ └── iamctl.go
│ └── iam-pump
│ └── pump.go
├── configs
├── CONTRIBUTING.md
├── deployments
├── docs
│ ├── devel
│ │ ├── en-US
│ │ └── zh-CN
│ ├── guide
│ │ ├── en-US
│ │ └── zh-CN
│ ├── images
│ └── README.md
├── examples
├── githooks
├── go.mod
├── go.sum
├── init
├── internal
│ ├── apiserver
│ │ ├── api
│ │ │ └── v1
│ │ │ └── user
│ │ ├── apiserver.go
│ │ ├── options
│ │ ├── service
│ │ ├── store
│ │ │ ├── mysql
│ │ │ ├── fake
│ │ └── testing
│ ├── authzserver
│ │ ├── api
│ │ │ └── v1
│ │ │ └── authorize
│ │ ├── options
│ │ ├── store
│ │ └── testing
│ ├── iamctl
│ │ ├── cmd
│ │ │ ├── completion
│ │ │ ├── user
│ │ └── util
│ ├── pkg
│ │ ├── code
│ │ ├── options
│ │ ├── server
│ │ ├── util
│ │ └── validation
├── LICENSE
├── Makefile
├── _output
│ ├── platforms
│ │ └── linux
│ │ └── amd64
├── pkg
│ ├── util
│ │ └── genutil
├── README.md
├── scripts
│ ├── lib
│ ├── make-rules
├── test
│ ├── testdata
├── third_party
│ └── forked
└── tools
一个 Go 项目包含 3 大部分:Go 应用 、项目管理和文档。所以,我们的项目目录也可以分为这 3 大类。同时,Go 应用又贯穿开发阶段、测试阶段和部署阶段,相应的应用类的目录,又可以按开发流程分为更小的子类。当然了,这些是我建议的目录,Go 项目目录中还有一些不建议的目录。所以整体来看,我们的目录结构可以按下图所示的方式来分类:
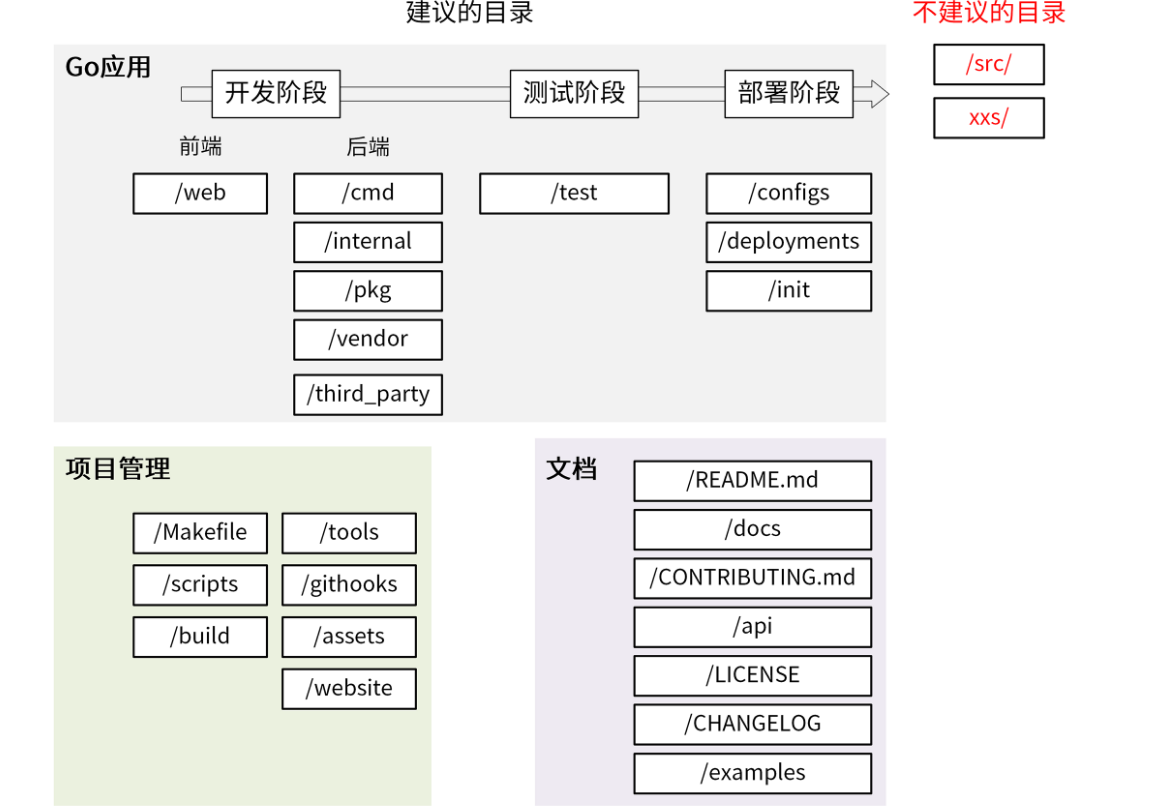
Go 应用 :主要存放前后端代码
/web:前端代码存放目录,主要用来存放 Web 静态资源,服务端模板和单页应用(SPAs)。
cmd
/cmd:一个项目有很多组件,可以把组件 main 函数所在的文件夹统一放在/cmd 目录下,例如:$ ls cmd/ gendocs geniamdocs genman genswaggertypedocs genyaml iam-apiserver iam-authz-server iamctl iam-pump $ ls cmd/iam-apiserver/ apiserver.go每个组件的目录名应该跟你期望的可执行文件名是一致的。这里要保证
/cmd/<组件名>目录下不要存放太多的代码,如果你认为代码可以导入并在其他项目中使用,那么它应该位于/pkg目录中。如果代码不是可重用的,或者你不希望其他人重用它,请将该代码放到/internal目录中。
internal
/internal:存放私有应用和库代码。如果一些代码,你不希望在其他应用和库中被导入,可以将这部分代码放在/internal 目录下。其他项目导入
/internal下的包时候,Go语言会编译出错:An import of a path containing the element “internal” is disallowed if the importing code is outside the tree rooted at the parent of the "internal" directory.可以通过 Go 语言本身的机制来约束其他项目 import 项目内部的包。/internal 目录建议包含如下目录:
/internal/apiserver:该目录中存放真实的应用代码。这些应用的共享代码存放在/internal/pkg 目录下。/internal/pkg:存放项目内可共享,项目外不共享的包。这些包提供了比较基础、通用的功能,例如工具、错误码、用户验证等功能。
我的建议是,一开始将所有的共享代码存放在 /internal/pkg 目录下,当该共享代码做好了对外开发的准备后,再转存到/pkg目录下。
├── apiserver
│ ├── api
│ │ └── v1
│ │ └── user
│ ├── options
│ ├── config
│ ├── service
│ │ └── user.go
│ ├── store
│ │ ├── mysql
│ │ │ └── user.go
│ │ ├── fake
│ └── testing
├── authzserver
│ ├── api
│ │ └── v1
│ ├── options
│ ├── store
│ └── testing
├── iamctl
│ ├── cmd
│ │ ├── cmd.go
│ │ ├── info
└── pkg
├── code
├── middleware
├── options
└── validation
/internal 目录大概分为 3 类子目录:
/internal/pkg:内部共享包存放的目录。/internal/authzserver、/internal/apiserver、/internal/pump、/internal/iamctl:应用目录,里面包含应用程序的实现代码。/internal/iamctl:对于一些大型项目,可能还会需要一个客户端工具。
在每个应用程序内部,也会有一些目录结构,这些目录结构主要根据功能来划分:
/internal/apiserver/api/v1:HTTP API 接口的具体实现,主要用来做 HTTP 请求的解包、参数校验、业务逻辑处理、返回。注意这里的业务逻辑处理应该是轻量级的,如果业务逻辑比较复杂,代码量比较多,建议放到 /internal/apiserver/service 目录下。该源码文件主要用来串流程。/internal/apiserver/options:应用的 command flag。/internal/apiserver/config:根据命令行参数创建应用配置。/internal/apiserver/service:存放应用复杂业务处理代码。/internal/apiserver/store/mysql:一个应用可能要持久化的存储一些数据,这里主要存放跟数据库交互的代码,比如 Create、Update、Delete、Get、List 等。
/internal/pkg 目录存放项目内可共享的包,通常可以包含如下目录:
/internal/pkg/code:项目业务 Code 码。/internal/pkg/validation:一些通用的验证函数。/internal/pkg/middleware:HTTP 处理链。
pkg
/pkg 目录是 Go 语言项目中非常常见的目录,我们几乎能够在所有知名的开源项目(非框架)中找到它的身影,例如 Kubernetes、Prometheus、Moby、Knative 等。
该目录中存放可以被外部应用使用的代码库,其他项目可以直接通过 import 导入这里的代码。所以,我们在将代码库放入该目录时一定要慎重。
/vendor
项目依赖,可通过 go mod vendor 创建。需要注意的是,如果是一个 Go 库,不要提交 vendor 依赖包。
/third_party
外部帮助工具,分支代码或其他第三方应用(例如 Swagger UI)。比如我们 fork 了一个第三方 go 包,并做了一些小的改动,我们可以放在目录 /third_party/forked 下。一方面可以很清楚的知道该包是 fork 第三方的,另一方面又能够方便地和 upstream 同步。
Go 应用:主要存放测试相关的文件和代码
/test
用于存放其他外部测试应用和测试数据。/test 目录的构建方式比较灵活:对于大的项目,有一个数据子目录是有意义的。例如,如果需要 Go 忽略该目录中的内容,可以使用 /test/data 或 /test/testdata 目录。
需要注意的是,Go 也会忽略以“.”或 “_” 开头的目录或文件。这样在命名测试数据目录方面,可以具有更大的灵活性。
Go 应用:存放跟应用部署相关的文件
接着,我们再来看下与部署阶段相关的目录,这些目录可以存放部署相关的文件。
/configs
这个目录用来配置文件模板或默认配置。例如,可以在这里存放 confd 或 consul-template 模板文件。这里有一点要注意,配置中不能携带敏感信息,这些敏感信息,我们可以用占位符来替代,例如:
apiVersion: v1
user:
username: ${CONFIG_USER_USERNAME} # iam 用户名
password: ${CONFIG_USER_PASSWORD} # iam 密码
/deployments
用来存放 Iaas、PaaS 系统和容器编排部署配置和模板(Docker-Compose,Kubernetes/Helm,Mesos,Terraform,Bosh)。在一些项目,特别是用 Kubernetes 部署的项目中,这个目录可能命名为 deploy。
为什么要将这类跟 Kubernetes 相关的目录放到目录结构中呢?主要是因为当前软件部署基本都在朝着容器化的部署方式去演进。
/init
存放初始化系统(systemd,upstart,sysv)和进程管理配置文件(runit,supervisord)。比如 sysemd 的 unit 文件。这类文件,在非容器化部署的项目中会用到。
项目管理:存放用来管理 Go 项目的各类文件
在做项目开发时,还有些目录用来存放项目管理相关的文件,这里我们一起来看下。
/Makefile
虽然 Makefile 是一个很老的项目管理工具,但它仍然是最优秀的项目管理工具。所以,一个 Go 项目在其根目录下应该有一个 Makefile 工具,用来对项目进行管理,Makefile 通常用来执行静态代码检查、单元测试、编译等功能。其他常见功能,你可以参考这里:
- 静态代码检查(lint):推荐用 golangci-lint。
- 单元测试(test):运行 go test ./...。
- 编译(build):编译源码,支持不同的平台,不同的 CPU 架构。
- 镜像打包和发布(image/image.push):现在的系统比较推荐用 Docker/Kubernetes 进行部署,所以一般也要有镜像构建功能。
- 清理(clean):清理临时文件或者编译后的产物。
- 代码生成(gen):比如要编译生成 protobuf pb.go 文件。
- 部署(deploy,可选):一键部署功能,方便测试。
- 发布(release):发布功能,比如:发布到 Docker Hub、github 等。
- 帮助(help):告诉 Makefile 有哪些功能,如何执行这些功能。
- 版权声明(add-copyright):如果是开源项目,可能需要在每个文件中添加版权头,这可以通过 Makefile 来添加。
- API 文档(swagger):如果使用 swagger 来生成 API 文档,这可以通过 Makefile 来生成。
我还有一条建议:直接执行 make 时,执行如下各项 format -> lint -> test -> build,如果是有代码生成的操作,还可能需要首先生成代码 gen -> format -> lint -> test -> build。
在实际开发中,我们可以将一些重复性的工作自动化,并添加到 Makefile 文件中统一管理。
/scripts
该目录主要用来存放脚本文件,实现构建、安装、分析等不同功能。不同项目,里面可能存放不同的文件,但通常可以考虑包含以下 3 个目录:
/scripts/make-rules:用来存放 makefile 文件,实现 /Makefile 文件中的各个功能。Makefile 有很多功能,为了保持它的简洁,我建议你将各个功能的具体实现放在/scripts/make-rules 文件夹下。/scripts/lib:shell 库,用来存放 shell 脚本。一个大型项目中有很多自动化任务,比如发布、更新文档、生成代码等,所以要写很多 shell 脚本,这些 shell 脚本会有一些通用功能,可以抽象成库,存放在/scripts/lib 目录下,比如 logging.sh,util.sh 等。/scripts/install:如果项目支持自动化部署,可以将自动化部署脚本放在此目录下。如果部署脚本简单,也可以直接放在 /scripts 目录下。
另外,shell 脚本中的函数名,建议采用语义化的命名方式,例如 iam::log::info 这种语义化的命名方式,可以使调用者轻松的辨别出函数的功能类别,便于函数的管理和引用。在 Kubernetes 的脚本中,就大量采用了这种命名方式。
/build
这里存放安装包和持续集成相关的文件。这个目录下有 3 个大概率会使用到的目录,在设计目录结构时可以考虑进去。
/build/package:存放容器(Docker)、系统(deb, rpm, pkg)的包配置和脚本。/build/ci:存放 CI(travis,circle,drone)的配置文件和脚本。/build/docker:存放子项目各个组件的 Dockerfile 文件。
tools
存放这个项目的支持工具。这些工具可导入来自 /pkg 和 /internal 目录的代码。
githooks
Git 钩子。比如,我们可以将 commit-msg 存放在该目录。
/assets
项目使用的其他资源 (图片、CSS、JavaScript 等)。
/website
如果你不使用 GitHub 页面,那么可以在这里放置项目网站相关的数据。
文档:主要存放项目的各类文档
一个项目,也包含一些文档,这些文档有很多类别,也需要一些目录来存放这些文档,这里我们也一起来看下。
/README.md
项目的 README 文件一般包含了项目的介绍、功能、快速安装和使用指引、详细的文档链接以及开发指引等。有时候 README 文档会比较长,为了能够快速定位到所需内容,需要添加 markdown toc 索引,可以借助工具 tocenize 来完成索引的添加。
/docs
存放设计文档、开发文档和用户文档等(除了 godoc 生成的文档)。推荐存放以下几个子目录:
/docs/devel/{en-US,zh-CN}:存放开发文档、hack 文档等。/docs/guide/{en-US,zh-CN}: 存放用户手册,安装、quickstart、产品文档等,分为中文文档和英文文档。/docs/images:存放图片文件。
/CONTRIBUTING.md
如果是一个开源就绪的项目,最好还要有一个 CONTRIBUTING.md 文件,用来说明如何贡献代码,如何开源协同等等。CONTRIBUTING.md 不仅能够规范协同流程,还能降低第三方开发者贡献代码的难度。
/api
/api 目录中存放的是当前项目对外提供的各种不同类型的 API 接口定义文件,其中可能包含类似 /api/protobuf-spec、/api/thrift-spec、/api/http-spec、openapi、swagger 的目录,这些目录包含了当前项目对外提供和依赖的所有 API 文件。例如,如下是 IAM 项目的 /api 目录:
├── openapi/
│ └── README.md
└── swagger/
├── docs/
├── README.md
└── swagger.yaml
二级目录的主要作用,就是在一个项目同时提供了多种不同的访问方式时,可以分类存放。用这种方式可以避免潜在的冲突,也能让项目结构更加清晰。
/examples
存放应用程序或者公共包的示例代码。这些示例代码可以降低使用者的上手门槛。
💡 在 Go 项目中,要避免使用带复数的目录或者包。建议统一使用单数。
合理的多人开发流
基于 master 分支新建一个功能分支,功能分支可以取一些有意义的名字,便于理解,例如 feature/rate-limiting。
$ git checkout -b feature/rate-limiting
在功能分支上进行代码开发,开发完成后 commit 到功能分支。
$ git add limit.go
$ git commit -m "add rate limiting"
将本地功能分支代码 push 到远程仓库。
$ git push origin feature/rate-limiting
在远程仓库上创建 PR(例如:GitHub)。
进入 GitHub 平台上的项目主页,点击 Compare & pull request 提交 PR,如下图所示。
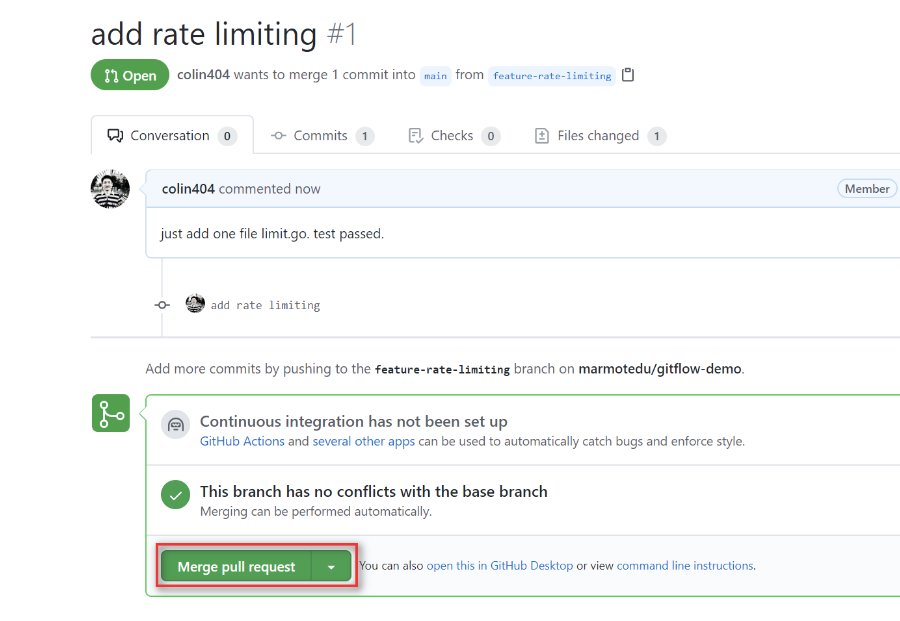
图中的“Merge pull request” 提供了 3 种 merge 方法:
- Create a merge commit:GitHub 的底层操作是 git merge --no-ff。feature 分支上所有的 commit 都会加到 master 分支上,并且会生成一个 merge commit。这种方式可以让我们清晰地知道是谁做了提交,做了哪些提交,回溯历史的时候也会更加方便。
- Squash and merge:GitHub 的底层操作是 git merge --squash。Squash and merge 会使该 pull request 上的所有 commit 都合并成一个 commit ,然后加到 master 分支上,但原来的 commit 历史会丢失。如果开发人员在 feature 分支上提交的 commit 非常随意,没有规范,那么我们可以选择这种方法来丢弃无意义的 commit。但是在大型项目中,每个开发人员都应该是遵循 commit 规范的,因此我不建议你在团队开发中使用 Squash and merge。
- Rebase and merge:GitHub 的底层操作是 git rebase。这种方式会将 pull request 上的所有提交历史按照原有顺序依次添加到 master 分支的头部(HEAD)。因为 git rebase 有风险,在你不完全熟悉 Git 工作流时,我不建议 merge 时选择这个。通过分析每个方法的优缺点,在实际的项目开发中,我比较推荐你使用 Create a merge commit 方式。
开源项目的贡献步骤:
这也是我们所需要的步骤,我们绝大多数需要的都是开源项目
Fork 远程仓库到自己的账号下。
将https://github.com/marmotedu/iam 项目 Fork 到自己的仓库 https://github.com/cubxxw/iam
$ git clone https://github.com/cubxxw/iam
$ cd gitflow-demo
$ git remote add upstream https://github.com/marmotedu/iam
$ git remote set-url --push upstream no_push # Never push to upstream master
$ git remote -v # Confirm that your remotes make sense
origin https://github.com/cubxxw/iam (fetch)
origin https://github.com/cubxxw/iam (push)
upstream https://github.com/marmotedu/iam (fetch)
upstream https://github.com/marmotedu/iam (push)
创建功能分支。
首先,要同步本地仓库的 master 分支为最新的状态(跟 upstream master 分支一致)。
$ git fetch upstream
$ git checkout master
$ git rebase upstream/master
然后,创建功能分支。
$ git checkout -b feature/add-function
提交 commit。
在 feature/add-function 分支上开发代码,开发完代码后,提交 commit。
$ git fetch upstream # commit 前需要再次同步 feature 跟 upstream/master
$ git rebase upstream/master
$ git add <file>
$ git status
$ git commit
分支开发完成后,可能会有一堆 commit,但是合并到主干时,我们往往希望只有一个(或最多两三个)commit,这可以使功能修改都放在一个或几个 commit 中,便于后面的阅读和维护。这个时候,我们可以用 git rebase 来合并和修改我们的 commit,操作如下:
$ git rebase -i origin/master
研发流程
一个项目从立项到结项,中间会经历很多阶段。业界相对标准的划分,是把研发流程分为六个阶段,分别是需求阶段、设计阶段、开发阶段、测试阶段、发布阶段、运营阶段。其中,开发人员需要参与的阶段有 4 个:设计阶段、开发阶段、测试阶段和发布阶段。下图就是业界相对比较标准的流程:
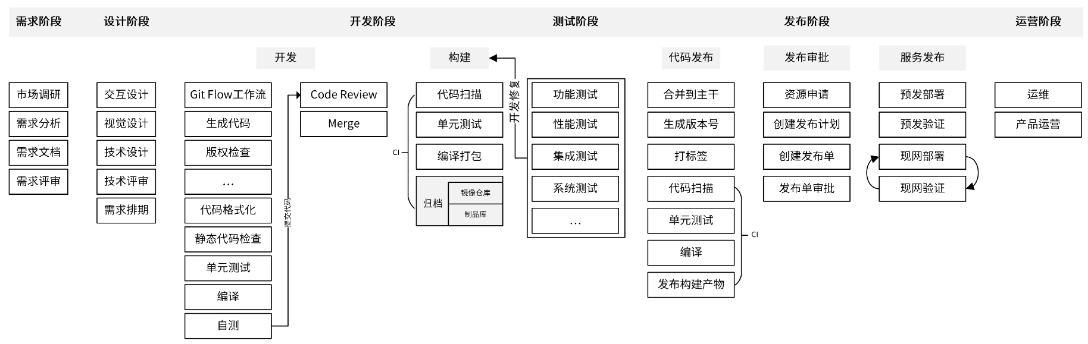
每个阶段结束时,都需要有一个最终的产出物,可以是文档、代码或者部署组件等。这个产出物既是当前阶段的结束里程碑,又是下一阶段的输入。所以说,各个阶段不是割裂的,而是密切联系的整体。每个阶段又细分为很多步骤,这些步骤是需要不同的参与者去完成的工作任务。在完成任务的过程中,可能需要经过多轮的讨论、修改,最终形成定稿。
需求阶段
需求阶段是将一个抽象的产品思路具化成一个可实施产品的阶段。在这个阶段,产品人员会讨论产品思路、调研市场需求,并对需求进行分析,整理出一个比较完善的需求文档。最后,产品人员会组织相关人员对需求进行评审,如果评审通过,就会进入设计阶段。
需求阶段,一般不需要研发人员参与。但这里,我还是建议你积极参与产品需求的讨论。虽然我们是研发,但我们的视野和对团队的贡献,可以不仅仅局限在研发领域。
这里有个点需要提醒你,如果你们团队有测试人员,这个阶段也需要拉测试人员旁听下。因为了解产品设计,对测试阶段测试用例的编写和功能测试等都很有帮助。
需求阶段的产出物是一个通过评审的详细的需求文档。
设计阶段
设计阶段,是整个产品研发过程中非常重要的阶段,包括的内容也比较多,你可以看一下这张表:

这里的每一个设计项都应该经过反复的讨论、打磨,最终在团队内达成共识。这样可以确保设计是合理的,并减少返工的概率。这里想提醒你的是,技术方案和实现都要经过认真讨论,并获得一致通过,否则后面因为技术方案设计不当,需要返工,你要承担大部分责任。
开发阶段
开发阶段,从它的名字你就知道了,这是开发人员的主战场,同时它可能也是持续时间最长的阶段。在这一阶段,开发人员根据技术设计文档,编码实现产品需求。
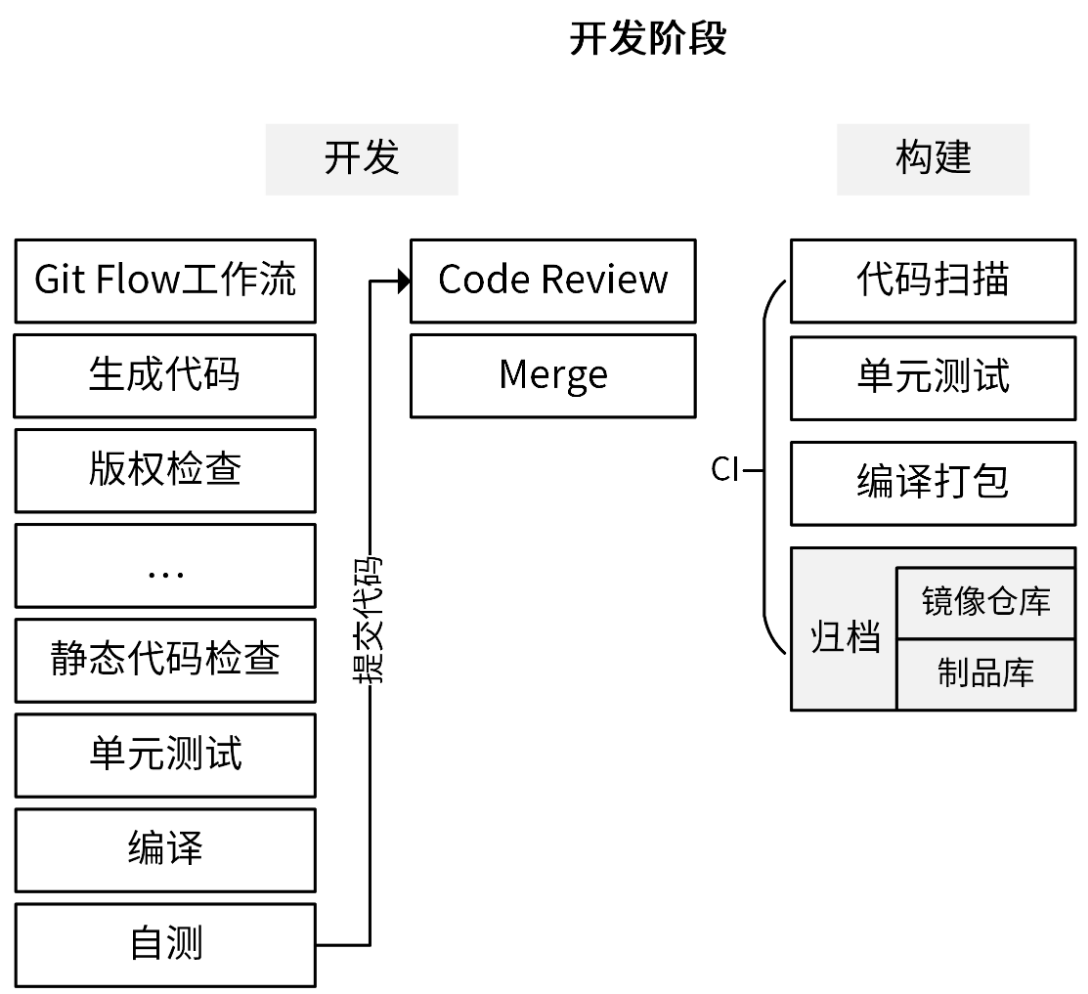
让我们来详细看下这张图里呈现的步骤。开发阶段又可以分为“开发”和“构建”两部分,我们先来看开发。
为了提高开发效率,越来越多的开发者采用生成代码的方式来生成一部分代码,所以在真正编译之前可能还需要先生成代码,比如生成 .pb.go 文件、API 文档、测试用例、错误码等。我的建议是,在项目开发中,你要思考怎么尽可能自动生成代码。这样不仅能提高研发效率,还能减少错误。
对于一个开源项目,我们可能还需要检查新增的文件是否有版权信息。此外,根据项目不同,开发阶段还可能有其它不同的步骤。在流程的最后,通常会进行静态代码检查、单元测试和编译。编译之后,我们就可以启动服务,并进行自测了。
自测之后,我们可以遵循 Git Flow 工作流,将开发分支 push 到代码托管平台进行 code review。code review 通过之后,我们就可以将代码 merge 到 develop 分支上。
接下来进入构建阶段。这一阶段最好借助 CI/CD 平台实现自动化,提高构建效率。
合并到 develop 分支的代码同样需要进行代码扫描、单元测试,并编译打包。最后,我们需要进行归档,也就是将编译后的二进制文件或 Docker 镜像上传到制品库或镜像仓库。
如何提高效率呢?两种方法:
- 将开发阶段的步骤通过 Makefile 实现集中管理;
- 将构建阶段的步骤通过 CI/CD 平台实现自动化。
在最终合并代码到 master 之前,要确保代码是经过充分测试的。
其中有一个代码覆盖率:
测试阶段
测试阶段由测试工程师(也叫质量工程师)负责,这个阶段的主要流程是:测试工程师根据需求文档创建测试计划、编写测试用例,并拉研发同学一起评审测试计划和用例。评审通过后,测试工程师就会根据测试计划和测试用例对服务进行测试。
为了提高整个研发效率,测试计划的创建和测试用例的编写可以跟开发阶段并行。
研发人员在交付给测试时,要提供自测报告、自测用例和安装部署文档。这里我要强调的是:在测试阶段,为了不阻塞测试,确保项目按时发布,研发人员应该优先解决测试同学的 Bug,至少是阻塞类的 Bug。为了减少不必要的沟通和排障,安装部署文档要尽可能详尽和准确。
另外,你也可以及时跟进测试,了解测试同学当前遇到的卡点。因为实际工作中,一些测试同学在遇到卡点时,不善于或者不会及时地跟你同步卡点,往往研发 1 分钟就可以解决的问题,可能要花测试同学几个小时或者更久的时间去解决。
发布阶段
发布阶段主要是将软件部署上线,为了保证发布的效率和质量,我们需要遵循一定的发布流程,如下图所示:
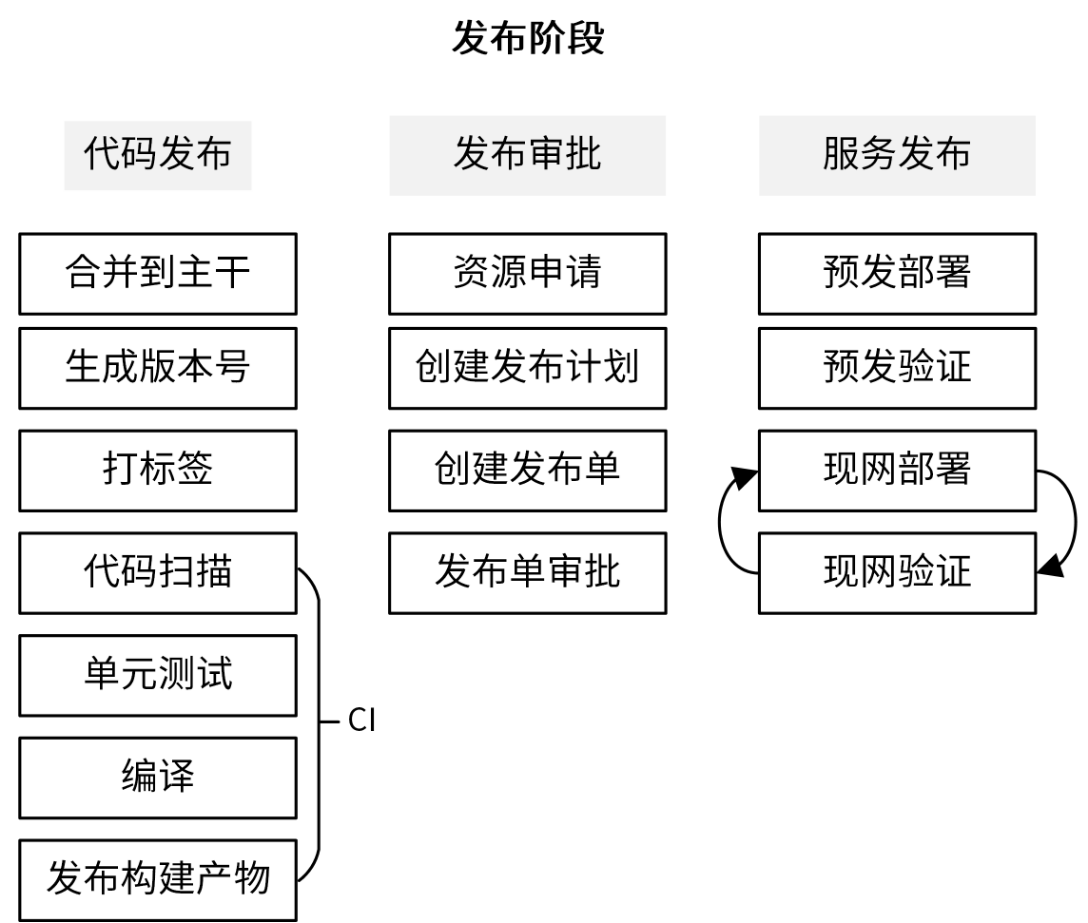
首先,开发人员首先需要将经过测试后的代码合并到主干,通常是 master 分支,并生成版本号,然后给最新的 commit 打上版本标签。之后,可以将代码 push 到代码托管平台,并触发 CI 流程,CI 流程一般会执行代码扫描、单元测试、编译,最后将构建产物发布到制品库。CI 流程中,我们可以根据需要添加任意功能。
编写一些自动化的测试用例,在服务发布到现网之后,对现网服务做一次比较充分的回归测试。通过这个自动化测试,可以以最小的代价,最快速地验证现网功能,从而保障发布质量。
运营阶段
研发流程的最后一个阶段是运营阶段,该阶段主要分为产品运营和运维两个部分。
- 产品运营:通过一系列的运营活动,比如线下的技术沙龙、线上的免费公开课、提高关键词排名或者输出一些技术推广文章等方式,来推高整个产品的知名度,提高产品的用户数量,并提高月活和日活。
- 运维:由运维工程师负责,核心目标是确保系统稳定的运行,如果系统异常,能够及时发现并修复问题。长期目标是通过技术手段或者流程来完善整个系统架构,减少人力投入、提高运维效率,并提高系统的健壮性和恢复能力。
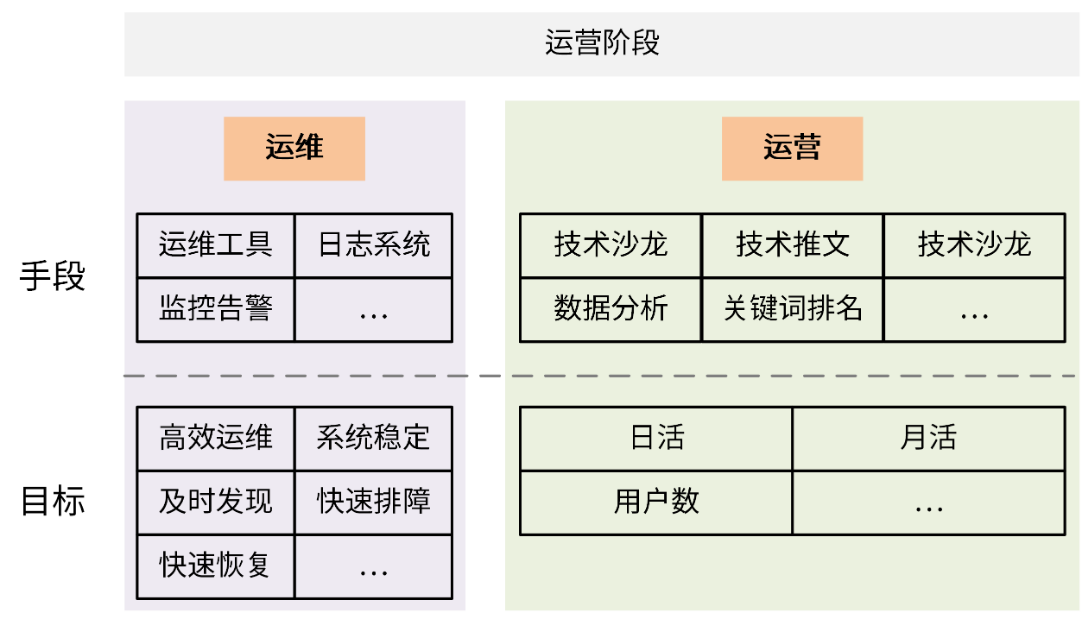
在运营阶段,研发人员的主要职责就是协助运维解决现网 Bug,优化部署架构。当然,研发人员可能也需要配合运营人员开发一些运营接口,供运营人员使用。
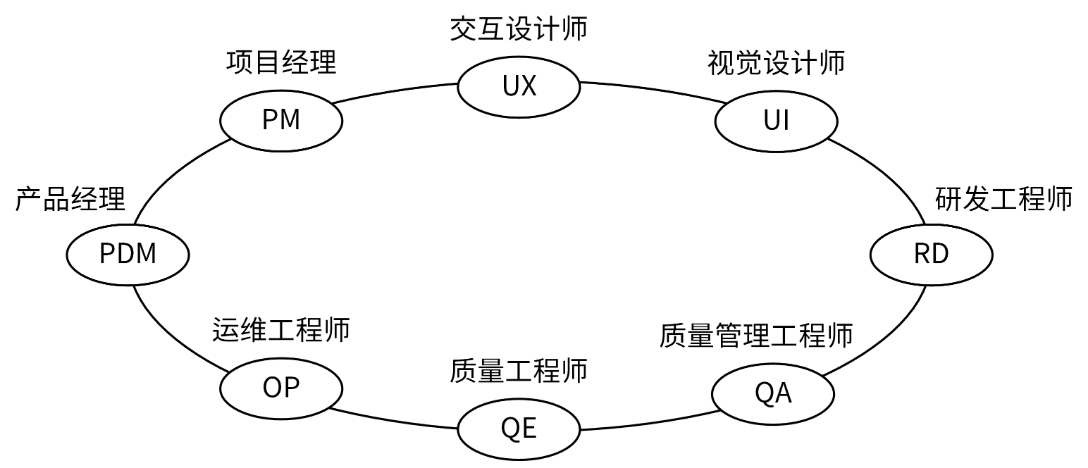
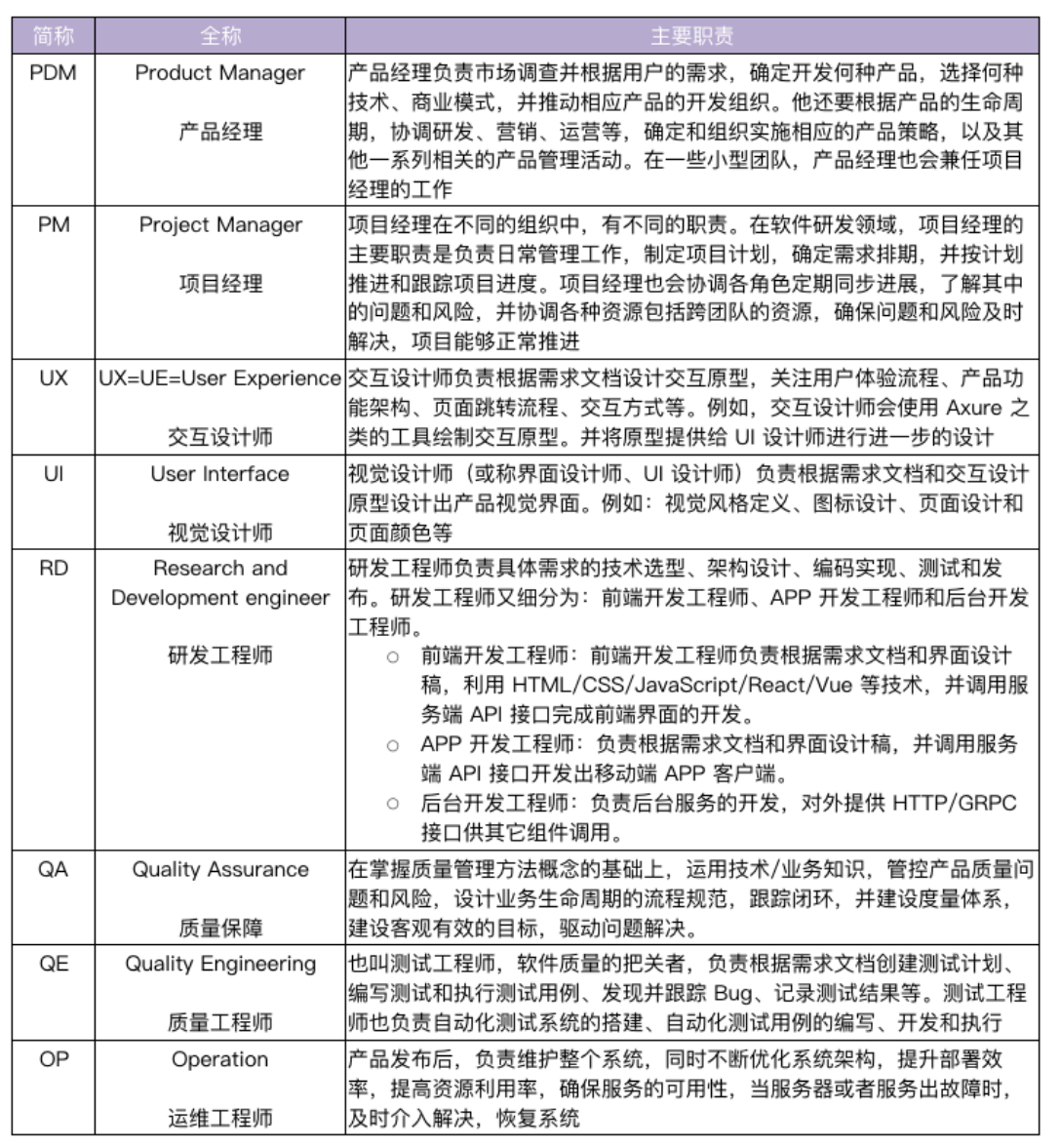
分工图:
如何管理应用生命周期
采用一些好的工具或方法在应用的整个生命周期中对应用进行管理,以提高应用的研发效率和质量。
在这里我先整体介绍一下,你先有个大致的印象,一会我们再一个个细讲。我们可以从两个维度来理解应用生命周期管理技术。
- 第一个维度是演进维度。应用生命周期,最开始主要是通过研发模式来管理的,按时间线先后出现了瀑布模式、迭代模式、敏捷模式。接着,为了解决研发模式中的一些痛点出现了另一种管理技术,也就是 CI/CD 技术。随着 CI/CD 技术的成熟,又催生了另一种更高级的管理技术 DevOps。
- 第二个维度是管理技术的类别。应用生命周期管理技术可以分为两类:
- 研发模式,用来确保整个研发流程是高效的。
- DevOps,主要通过协调各个部门之间的合作,来提高软件的发布效率和质量。DevOps 中又包含了很多种技术,主要包括 CI/CD 和多种 Ops,例如 AIOps、ChatOps、GitOps、NoOps 等。其中,CI/CD 技术提高了软件的发布效率和质量,而 Ops 技术则提高了软件的运维和运营效率。
尽管这些应用生命周期管理技术有很多不同,但是它们彼此支持、相互联系。研发模式专注于开发过程,DevOps 技术里的 CI/CD 专注于流程,Ops 则专注于实战。
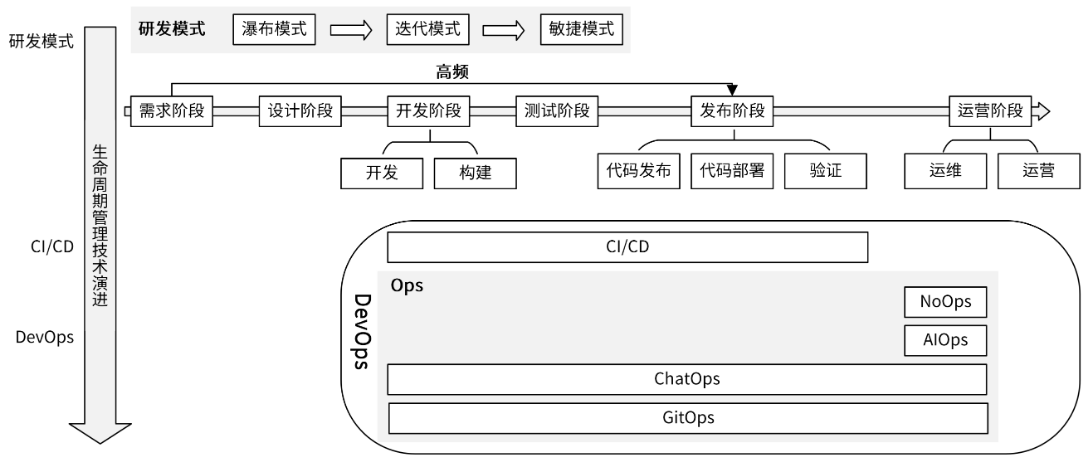
也就是按照这样的顺序:研发模式(瀑布模式 -> 迭代模式 -> 敏捷模式) -> CI/CD -> DevOps。
研发模式
研发模式主要有三种,演进顺序为瀑布模式 -> 迭代模式 -> 敏捷模式,现在我们逐一看下。
瀑布模式
在早期阶段,软件研发普遍采用的是瀑布模式,像我们熟知的 RHEL、Fedora 等系统就是采用瀑布模式。
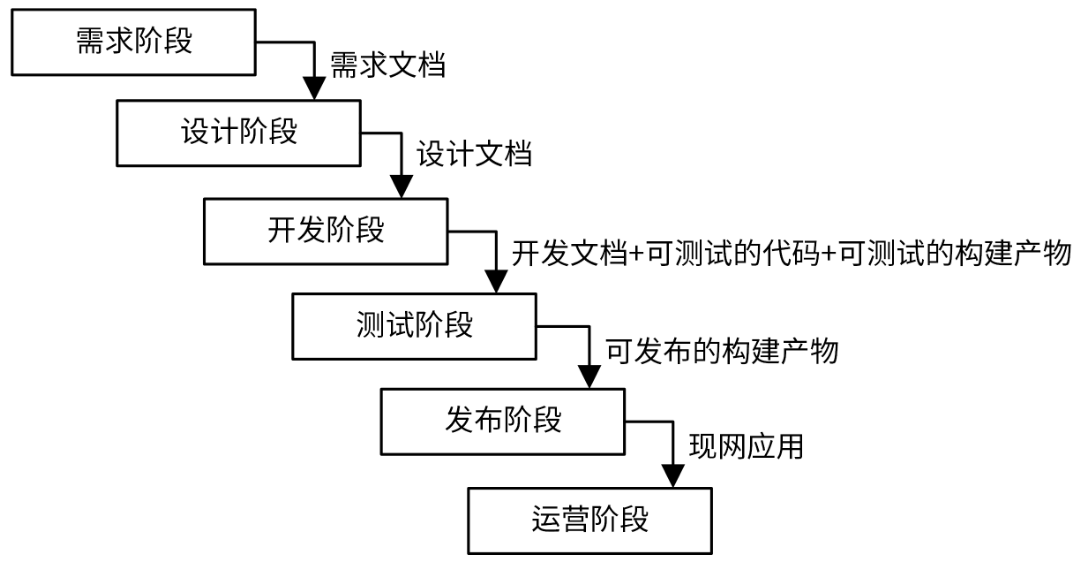
瀑布模式按照预先规划好的研发阶段来推进研发进度。比如,按照需求阶段、设计阶段、开发阶段、测试阶段、发布阶段、运营阶段的顺序串行执行开发任务。每个阶段完美完成之后,才会进入到下一阶段,阶段之间通过文档进行交付。整个过程如下图所示。
迭代模式
迭代模式,是一种与瀑布式模式完全相反的开发过程:研发任务被切分为一系列轮次,每一个轮次都是一个迭代,每一次迭代都是一个从设计到实现的完整过程。它不要求每一个阶段的任务都做到最完美,而是先把主要功能搭建起来,然后再通过客户的反馈信息不断完善。
迭代开发可以帮助产品改进和把控进度,它的灵活性极大地提升了适应需求变化的能力,克服了高风险、难变更、复用性低的特点。
但是,迭代模式的问题在于比较专注于开发过程,很少从项目管理的视角去加速和优化项目开发过程。接下来要讲的敏捷模式,就弥补了这个缺点。
敏捷模式
敏捷模式把一个大的需求分成多个、可分阶段完成的小迭代,每个迭代交付的都是一个可使用的软件。在开发过程中,软件要一直处于可使用状态。
在敏捷模式中,我们会把一个大的需求拆分成很多小的迭代,这意味着开发过程中会有很多个开发、构建、测试、发布和部署的流程。这种高频度的操作会给研发、运维和测试人员带来很大的工作量,降低了工作效率。为了解决这个问题,CI/CD 技术诞生了。
CI/CD:自动化构建和部署应用
CI/CD 技术通过自动化的手段,来快速执行代码检查、测试、构建、部署等任务,从而提高研发效率,解决敏捷模式带来的弊端。
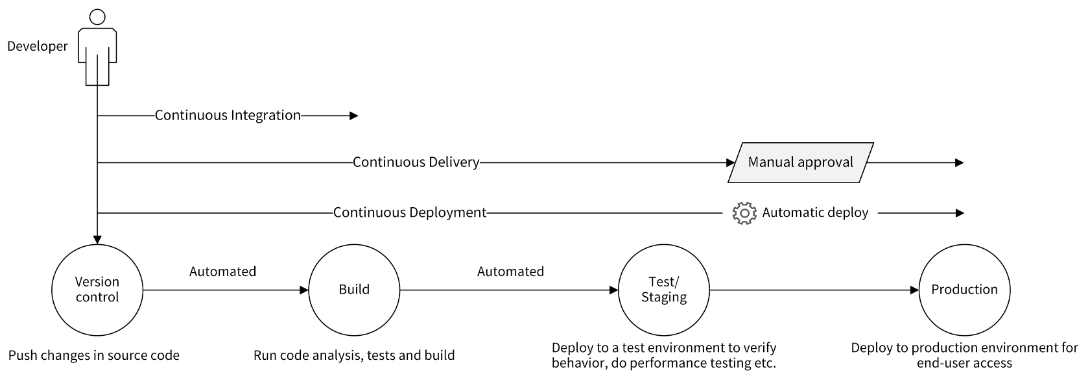
CI/CD 包含了 3 个核心概念。
- CI:Continuous Integration,持续集成。
- CD:Continuous Delivery,持续交付。
- CD:Continuous Deployment,持续部署。
CI 容易理解,但两个 CD 很多开发者区分不开。这里,我来详细说说这 3 个核心概念。
首先是持续集成。它的含义为:频繁地(一天多次)将开发者的代码合并到主干上。它的流程为:在开发人员完成代码开发,并 push 到 Git 仓库后,CI 工具可以立即对代码进行扫描、(单元)测试和构建,并将结果反馈给开发者。持续集成通过后,会将代码合并到主干。
CI 流程可以使应用软件的问题在开发阶段就暴露出来,这会让开发人员交付代码时更有信心。因为 CI 流程内容比较多,而且执行比较频繁,所以 CI 流程需要有自动化工具来支撑。
其次是持续交付,它指的是一种能够使软件在较短的循环中可靠发布的软件方法。
持续交付在持续集成的基础上,将构建后的产物自动部署在目标环境中。这里的目标环境,可以是测试环境、预发环境或者现网环境。
通常来说,持续部署可以自动地将服务部署到测试环境或者预发环境。因为部署到现网环境存在一定的风险,所以如果部署到现网环境,需要手工操作。手工操作的好处是,可以使相关人员评估发布风险,确保发布的正确性。
最后是持续部署,持续部署在持续交付的基础上,将经过充分测试的代码自动部署到生产环境,整个流程不再需要相关人员的审核。持续部署强调的是自动化部署,是交付的最高阶段。
持续集成、持续交付和持续部署强调的是持续性,也就是能够支持频繁的集成、交付和部署,这离不开自动化工具的支持,离开了这些工具,CI/CD 就不再具有可实施性。持续集成的核心点在代码,持续交付的核心点在可交付的产物,持续部署的核心点在自动部署。
DevOps:研发运维一体化
CI/CD 技术的成熟,加速了 DevOps 这种应用生命周期管理技术的成熟和落地。
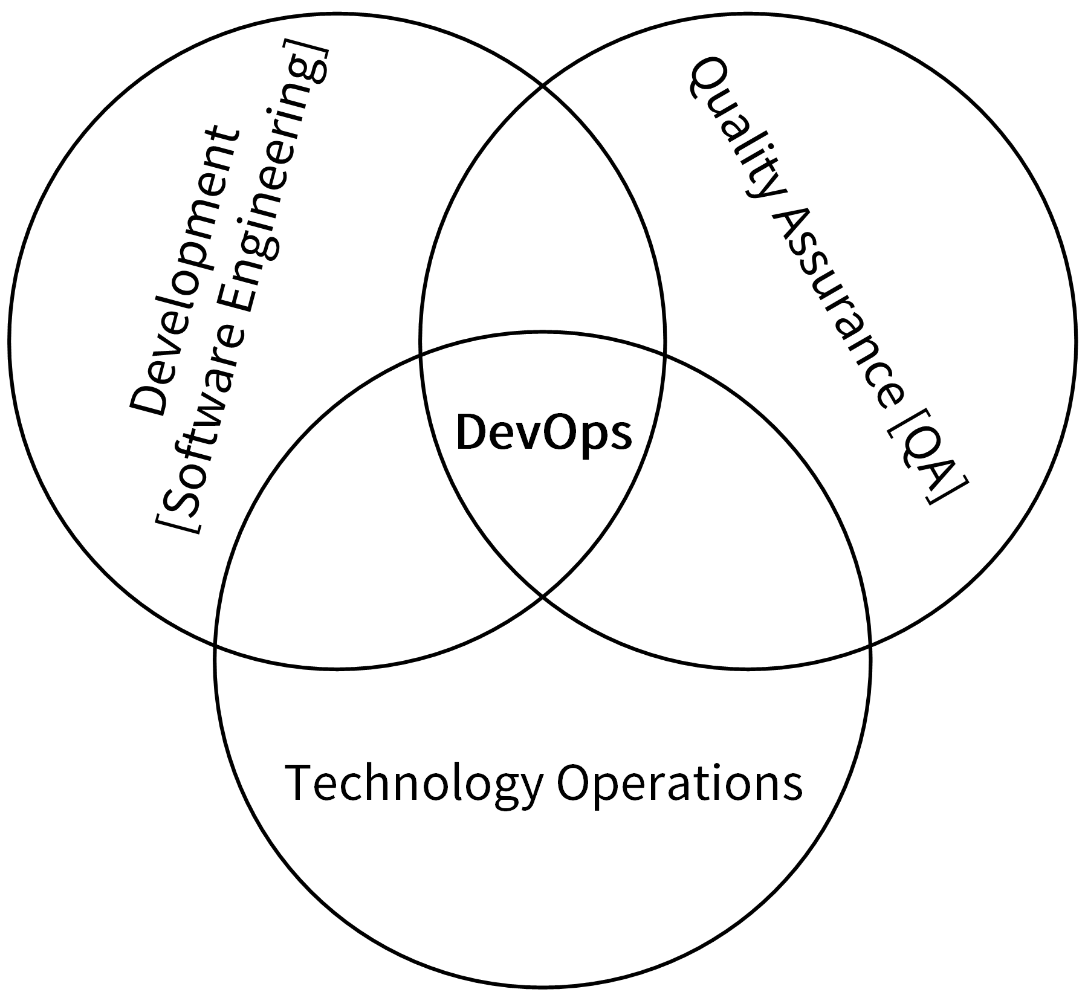
DevOps(Development 和 Operations 的组合)是一组过程、方法与系统的统称,用于促进开发(应用程序 / 软件工程)、技术运营和质量保障(QA)部门之间的沟通、协作与整合。这 3 个部门的相互协作,可以提高软件质量、快速发布软件。如下图所示:
要实现 DevOps,需要一些工具或者流程的支持,CI/CD 可以很好地支持 DevOps 这种软件开发模式,如果没有 CI/CD 自动化的工具和流程,DevOps 就是没有意义的,CI/CD 使得 DevOps 变得可行。
DevOps != CI/CD。DevOps 是一组过程、方法和系统的统称,而 CI/CD 只是一种软件构建和发布的技术。
DevOps 技术之前一直有,但是落地不好,因为没有一个好的工具来实现 DevOps 的理念。但是随着容器、CI/CD 技术的诞生和成熟,DevOps 变得更加容易落地。也就是说,这几年越来越多的人采用 DevOps 手段来提高研发效能。
随着技术的发展,目前已经诞生了很多 Ops 手段,来实现运维和运营的高度自动化。下面,我们就来看看 DevOps 中的四个 Ops 手段:AIOps、ChatOps、GitOps、NoOps。
AIOps:智能运维
在 2016 年,Gartner 提出利用 AI 技术的新一代 IT 运维,即 AIOps(智能运维)。通过 AI 手段,来智能化地运维 IT 系统。AIOps 通过搜集海量的运维数据,并利用机器学习算法,智能地定位并修复故障。
也就是说,AIOps 在自动化的基础上,增加了智能化,从而进一步推动了 IT 运维自动化,减少了人力成本。
随着 IT 基础设施规模和复杂度的倍数增长,企业应用规模、数量的指数级增长,传统的人工 / 自动化运维,已经无法胜任愈加沉重的运维工作,而 AIOps 提供了一个解决方案。在腾讯、阿里等大厂很多团队已经在尝试和使用 AIOps,并享受到了 AIOps 带来的红利。例如,故障告警更加灵敏、准确,一些常见的故障,可以自动修复,无须运维人员介入等。
ChatOps:聊着天就把事情给办了
随着企业微信、钉钉等企业内通讯工具的兴起,最近几年出现了一个新的概念 ChatOps。
简单来说,ChatOps 就是在一个聊天工具中,发送一条命令给 ChatBot 机器人,然后 ChatBot 会执行预定义的操作。这些操作可以是执行某个工具、调用某个接口等,并返回执行结果。
这种新型智能工作方式的优势是什么呢?它可以利用 ChatBot 机器人让团队成员和各项辅助工具连接在一起,以沟通驱动的方式完成工作。ChatOps 可以解决人与人、人与工具、工具与工具之间的信息孤岛,从而提高协作体验和工作效率。
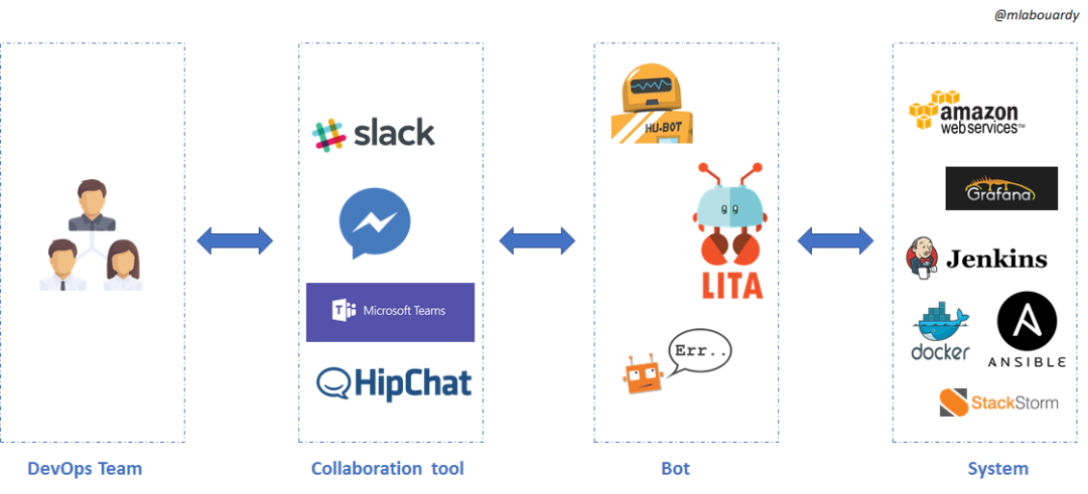
开发 / 运维 / 测试人员通过 @聊天窗口中的机器人 Bot 来触发任务,机器人后端会通过 API 接口调用等方式对接不同的系统,完成不同的任务,例如持续集成、测试、发布等工作。机器人可以是我们自己研发的,也可以是开源的。目前,业界有很多流行的机器人可供选择,常用的有 Hubot、Lita、Errbot、StackStorm 等。
GitOps: 一种实现云原生的持续交付模型
GitOps 是一种持续交付的方式。它的核心思想是将应用系统的声明性基础架构(YAML)和应用程序存放在 Git 版本库中。将 Git 作为交付流水线的核心,每个开发人员都可以提交拉取请求(Pull Request),并使用 Git 来加速和简化 Kubernetes 的应用程序部署和运维任务。
通过 Git 这样的工具,开发人员可以将精力聚焦在功能开发,而不是软件运维上,以此提高软件的开发效率和迭代速度。
使用 GitOps 可以带来很多优点,其中最核心的是:当使用 Git 变更代码时,GitOps 可以自动将这些变更应用到程序的基础架构上。因为整个流程都是自动化的,所以部署时间更短;又因为 Git 代码是可追溯的,所以我们部署的应用也能够稳定且可重现地回滚。
我们可以从概念和流程上来理解 GitOps,它有 3 个关键概念:
- 声明性容器编排:通过 Kubernetes YAML 格式的资源定义文件,来定义如何部署应用。
- 不可变基础设施:基础设施中的每个组件都可以自动的部署,组件在部署完成后,不能发生变更。如果需要变更,则需要重新部署一个新的组件。例如,Kubernetes 中的 Pod 就是一个不可变基础设施。
- 连续同步:不断地查看 Git 存储库,将任何状态更改反映到 Kubernetes 集群中。
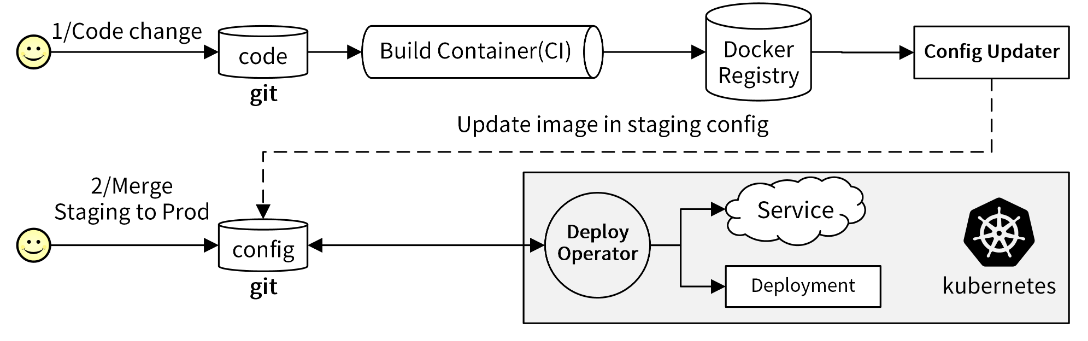
GitOps 的工作流程如下:
- 首先,开发人员开发完代码后推送到 Git 仓库,触发 CI 流程,CI 流程通过编译构建出 Docker 镜像,并将镜像 push 到 Docker 镜像仓库中。Push 动作会触发一个 push 事件,通过 webhook 的形式通知到 Config Updater 服务,Config Updater 服务会从 webhook 请求中获取最新 push 的镜像名,并更新 Git 仓库中的 Kubernetes YAML 文件。
- 然后,GitOps 的 Deploy Operator 服务,检测到 YAML 文件的变动,会重新从 Git 仓库中提取变更的文件,并将镜像部署到 Kubernetes 集群中。Config Updater 和 Deploy Operator 两个组件需要开发人员设计开发。
NoOps:无运维
NoOps 即无运维,完全自动化的运维。在 NoOps 中不再需要开发人员、运营运维人员的协同,把微服务、低代码、无服务全都结合了起来,开发者在软件生命周期中只需要聚焦业务开发即可,所有的维护都交由云厂商来完成。
毫无疑问,NoOps 是运维的终极形态,在我看来它像 DevOps 一样,更多的是一种理念,需要很多的技术和手段来支撑。当前整个运维技术的发展,也是朝着 NoOps 的方向去演进的,例如 GitOps、AIOps 可以使我们尽可能减少运维,Serverless 技术甚至可以使我们免运维。相信未来 NoOps 会像现在的 Serverless 一样,成为一种流行的、可落地的理念。
END 链接
✴️版权声明 © :本书所有内容遵循CC-BY-SA 3.0协议(署名-相同方式共享)©